|
רשימות מקושרות
בפרק הקודם הצגנו מצביעים.
טיפוס מצביע מאפשר לנו להגדיר מבני נתונים דינאמיים נוספים, כגון רשימה מקושרת.
רשימה מקושרת היא מבנה נתונים בו כל איבר מצביע על האיבר הבא אחריו.
כלומר כל איבר יכיל את השדות ה"רגילים" - מטיפוסים פשוטים שונים (שלם, ממשי וכו') או אף מבנים וכן לפחות שדה אחד מטיפוס מצביע.
היתרון הוא כפי שהזכרנו בפרק בקודם חיסכון בזיכרון ויכולת להגדלה או הקטנה של מבני הנתונים.
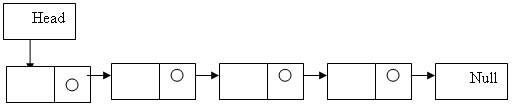
כל איבר ברשימה נקרא צומת, כאשר הצומת הראשונה היא ראש הרשימה והאחרונה סוף הרשימה, שלא מצביעה על אף איבר (מכיל null).
סימון:
משתנה מסוג רשימה- מלבן עם עיגול בתוכו.
מלבן - נתונים.
כל איבר ברשימה מכיל מצביע לאיבר הבא ונתונים חוץ מראש הרשימה שהוא
מכיל רק את הכתובת של האיבר הראשון ברשימה
 תבנית:
תבנית:
| |
struct list
{
data
...
...
struct list *next;
};
|
כל איבר ברשימה הוא בעל המבנה הנ"ל כלומר מכיל בחלקו הראשון נתונים ובחלקו השני מצביע לאיבר הבא.
דוגמאות:
| |
struct list
{
int num;
struct list *next;
};
|
| |
struct student
{
char f_name[10];
char l_name[10];
int frade;
struct student *next;
};
|
נתבונן ב list (שהוגדר).
נניח כי list בעלת 4 איברים (כמו בתרשים) ,נגדיר את ראש הרשימה כ- head .
Head מכיל את הכתובת של האיבר הראשון ברשימה. על מנת לפנות לאיבר הראשון נשתמש באופרטור * : *head - כך נוכל לקבל את התוכן של הכתובת ב head שהוא מבנה עם שני שדות המסומנים על ידי head->num ו head->next.
גם על מנת לגשת לשדות num ו- next ניתן בעזרת האופרטור *: (*head).next או (*head).num, אך נשתמש באופרטור -> לכתיבה מקוצרת.
הוספת איברים לתחילת הרשימה (add)
| |
void add (struct list** head, int num)
{
struct list* second = *head;
*head = (struct list*)malloc(sizeof(struct list));
(*head)->num = num;
(*head)->next = second;
}
|
נניח כי בפונקציה main() יש משתנה מצביע לרשימה (הוא בעצם ראש הרשימה ומקובל לקרוא לו head), שתוכנו הוא הכתובת של האיבר הראשון ברשימה. כשאנו מעוניינים לצרף איברים לרשימה יש צורך לשלוח את הכתובת של ראש הרשימה (כדי לבצע עידכונים ברשימה) ולכן הפרמטר שנשלח לפונקציה add הוא מצביע למצביע לרשימה - כך שהתוכן של המשתנה head החדש הוא הכתובת של ראש הרשימה (head של הפונקציה main()). תוכנו של *head החדש הוא הכתובת של האיבר הראשון שנוסף כעת לרשימה (בכניסה הראשונה האיבר הראשון של הרשימה הוא null כלומר הרשימה ריקה).
בפונקציה add() אנו מצהירים על משתנה second מסוג רשימה שמטרתו לשמור על הכתובת של האיבר הראשון ברשימה המקורית.
בשורה הבאה בונים את האיבר הראשון - מקצים כתובת חדשה וממלאים את השדות בערכים. לאחר מכן האיבר החדש שלנו יצביע על האיבר הראשון הקודם (שהיה ריק( ולכן האיבר הראשון מצביע על null.
בפעם הבאה נבנה שוב איבר ראשון חדש לרשימה אך הפעם הוא יצביע על האיבר הקודם של ראש הרשימה והרי ערכו שונה מ- null. כך יבנו כל האיברים.
הצגת הרשימה (display)
| |
void display_list (struct list* head)
{
struct list* temp = head;
printf ("\nThe members of the list are: \n\n");
while (temp != NULL)
{
printf (" %d ", temp->num);
temp = temp->next;
}
temp = head;
printf("\n");
while (temp != NULL)
{
printf ("%p ", temp);
temp = temp->next;
}
}
|
Head הוא הכתובת של האיבר הראשון ברשימה והוא נשמר במשתנה temp (אסור לקדם את head מכיוון שאם נעשה זאת נאבד את המצביע ולא נוכל יותר לגשת למקומות אלו בזיכרון). בתחילה מציגים את השדות של האיברים עד שמגיעים לסוף הרשימה אח"כ שוב temp מקבל את הכתובת של האיבר הראשון ברשימה ואז מציגים את הכתובות של אברי הרשימה.
מחיקת הרשימה (del)
| |
void del_member (struct list** head)
{
struct list *temp = *head;
*head = (*head)->next;
printf ("%p\t", temp);
free(temp);
}
|
| |
void delete_list (struct list** head)
{
printf("\n\nDeleting the list\n");
while (*head)
del_member (head);
}
|
את פעולת מחיקת הרשימה נעשה בשני שלבים - בשלב הראשון נעבור על איברי הרשימה כל עוד הרשימה לא ריקה ובשלב השני נמחק את האיברים. התהליך מתבצע בצורה הבאה:
הפונקציה del_member() מקבלת כארגומנט את הכתובת של ראש הרשימה (כעתhead החדש מכיל את הכתובת של ראש הרשימה ו- *head את הכתובת של האיבר הראשון ברשימה). כל עוד לא הגענו לסוף הרשימה היא שולחת את head שמכיל את הכתובת של ראש הרשימה לפונקציה del_member(), שם נשמרת הכתובת של האיבר הראשון של הרשימה במשתנה זמני הנקרא temp. האיבר הראשון ברשימה מקודם, כלומר כעת האיבר הראשון ברשימה החדשה הוא האיבר השני ברשימה הקודמת, ומשחררים על ידי הפונקציה free את האיבר הראשון הישן וכך הלאה לכל האיברים.
כעת נראה את התוכנית במלואה:
 דוגמא 1: דוגמא 1:
|
#include <stdio.h>
#include <conio.h>
#include <stdlib.h>
const int MAX = 3;
struct list
{
int num;
struct list *next;
};
void add (struct list** head, int num)
{
struct list* second = *head;
*head = (struct list*)malloc(sizeof(struct list));
(*head)->num = num;
(*head)->next = second;
}
void build_list (struct list** head)
{
int i, num;
for (i = 0; i < MAX; i++)
{
num = random(10);
add(head, num);
}
}
void display_list (struct list* head)
{
struct list* temp = head;
printf ("\nThe members of the list are: \n\n");
while (temp != NULL)
{
printf (" %d ", temp->num);
temp = temp->next;
}
temp = head;
printf("\n");
while (temp != NULL)
{
printf ("%p ", temp);
temp = temp->next;
}
}
void del_member (struct list** head)
{
struct list *temp = *head;
*head = (*head)->next;
printf ("%p\t", temp);
free(temp);
}
void delete_list (struct list** head)
{
printf("\n\nDeleting the list\n");
while (*head)
del_member (head);
}
void main()
{
struct list* head = NULL;
randomize();
build_list (&head);
display_list (head);
delete_list (&head);
}
|
 העבר את העכבר מעל הדוגמא כדי לראות הסבר מפורט העבר את העכבר מעל הדוגמא כדי לראות הסבר מפורט
הוספת איברים לסוף הרשימה (append)
| |
void append (int num, struct number** head, struct number** last)
{
struct number *newp =(struct number*)malloc(sizeof(struct number));
newp->num = num; //newp = new pointer
newp->next = NULL;
if (*head == NULL)
*head = newp;
else
(*last)->next = newp;
*last = newp
}
|
כדי להוסיף איברים לסוף הרשימה יש צורך לשמור את הכתובת של סוף הרשימה. כתובת זו נשמרת במשתנהlast ו-*head מכיל את הכתובת של האיבר הראשון ברשימה.
newp הוא זה שיהיה האיבר החדש והאחרון ברשימה (בכל יצירת איבר חדש) ולכן הוא יצביע על null (סוף הרשימה). בודקים אם הרשימה ריקה ואין בה איברים (יקרה בכל רשימה חדשה שנבנה) אז האיבר הראשון ברשימה *head הוא האיבר החדש שבנינו, ואם לא כלומר הרשימה לא ריקה אז מצרפים את האיבר החדש לסוף הרשימה.*last היא הכתובת של האיבר האחרון ברשימה - נדאג לעדכן את המצביע שלו לאיבר החדש שבנינו ואח"כ לעדכן את last שיצביע על האיבר החדש מאחר והוא החליף את האחרון הקודם. ניתן לראות כי האיבר האחרון מתעדכן כל פעם בהתאם לאיבר האחרון שנוסף.
דוגמא 2:
|
#include <stdio.h>
#include <conio.h>
#include <stdlib.h>
#include <time.h>
#define MAX 3
struct number
{
int num;
struct number *next;
};
void append (int num, struct number** head, struct number** last)
{
struct number *newp =(struct number*)malloc(sizeof(struct number));
newp->num = num; //newp = new pointer
newp->next = NULL;
if (*head == NULL)
*head = newp;
else
(*last)->next = newp;
*last = newp;
}
void read_2_list (struct number** head, struct number** last)
{
int array[MAX];
int i;
for (i = 0; i < MAX; i++)
{
array[i] = i+random(20);
append (array[i], head, last);
}
}
void display_list (struct number* head, char *msg)
{
struct number* temp = head;
printf ("\n %s",msg);
printf("\nThe address of the list is: %p", &head);
printf ("\nThe members of the list are: \n\n");
while (temp != NULL)
{
printf (" %d ", temp->num);
temp = temp->next;
}
temp = head;
printf("\n");
while (temp != NULL)
{
printf ("%p ", temp);
temp = temp->next;
}
}
void swap (int *a, int *b)
{
int temp = *a;
*a = *b;
*b = temp;
}
void sorting_list (struct number** head)
{
int i, j;
struct number* temp1 = *head;
struct number* temp2;
for ( ; temp1->next; temp1 = temp1->next)
{
temp2 = temp1->next;
for ( ; temp2; temp2 = temp2->next)
{
if (temp2->num > temp1->num)
swap(&temp2->num, &temp1->num);
}
}
}
void sum (struct number* head)
{
int sum = 0;
struct number* temp = head;
for (; temp; temp = temp->next)
sum += temp->num;
printf ("\nThe sum of the numbers in the list = %d", sum);
printf ("\nThe average of the numbers in the list = %f", (float)sum/MAX);
printf ("\nThe max number in the list = %d", head->num);
}
void del_member (struct number** head)
{
struct number *temp = *head;
*head = (*head)->next;
printf("%p\t",temp);
free(temp);
}
void delete_list (struct number** head)
{
printf("\n\nDeleting the list\n");
while (*head)
del_member (head);
}
void main()
{
struct number* head = NULL;
struct number* last;
randomize();
read_2_list (&head, &last);
display_list (head, "Display list of number before sorting");
sorting_list (&head);
display_list (head, "Display list of number after sorting");
sum (head);
delete_list (&head);
}
|
העבר את העכבר מעל הדוגמא כדי לראות הסבר מפורט
 הערה: למתעניינים במיונים - ישנם ספרים רבים בנושא, פה לא נתעמק בדרכי פעולתם. הערה: למתעניינים במיונים - ישנם ספרים רבים בנושא, פה לא נתעמק בדרכי פעולתם.
דוגמא 3:
| |
#include <conio.h>
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
struct employee
{
char f_name[10];
char l_name[10];
float wage;
};
struct node
{
employee emp;
struct node* next;
};
const MAX = 3;
employee read_data()
{
employee p;
printf("Enter your first name: ");
flushall();
gets(p.f_name);
printf("Enter your last name: ");
flushall();
gets(p.l_name);
printf("Enter your wage: ");
flushall();
scanf ("%f",&p.wage);
return p;
}
void append (struct node* &head, employee emp)
{
struct node* n_last = new node; //n_last = new last
static struct node* last;
n_last->emp = emp;
n_last->next = NULL;
if (head == NULL)
head = n_last;
else
last->next = n_last;
last = n_last;
}
void bulid_list (struct node* &head)
{
int i;
for (i = 0; i < MAX; i++)
append (head, read_data());
}
void read_2_file (struct node* &head, FILE *f)
{
f = fopen ("employee.txt", "wt");
struct node* temp = head;
while (temp != NULL)
{
fprintf (f, "%s %s %8.2f\n", temp->emp.f_name, temp->emp.l_name,temp->emp.wage);
temp = temp->next;
}
fclose(f);
}
void del_node (struct node* &head)
{
struct node* temp = head;
head = head->next;
free (temp);
}
void delete_list (struct node* &head)
{
printf("\n\nDeleting the list");
while (head)
del_node (head);
}
void display_list (struct node* head)
{
int i;
struct node* temp = head;
for (i = 0; temp ; i++)
{
printf ("\n %d", i);
printf (" %s %s %8.2f ", temp->emp.f_name,
temp->emp.l_name, temp->emp.wage);
temp = temp->next;
}
}
void sum_high (struct node* head)
{
struct node* max = head;
float sum = 0;
while (head)
{
if (max->emp.wage < head->emp.wage)
max = head;
sum += head->emp.wage;
head = head->next;
}
printf ("\n\nThe highest selary is: %6.2f", max->emp.wage);
printf ("\nThe sum of the selaries is: %10.2f", sum);
printf ("\n\nThe average of the selaries is: %6.2f",sum/MAX);
}
void main()
{
randomize();
struct node* head = NULL;
FILE *f;
bulid_list (head);
read_2_file (head, f);
display_list (head);
sum_high (head);
delete_list (head);
}
|
העבר את העכבר מעל הדוגמא כדי לראות הסבר מפורט
נסביר בהרחבה:
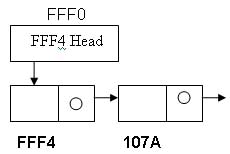
מכיוון ש- head הוא מטיפוס מצביע לרשימה (נניח יושב בכתובת fff4) ואנו מעוניינים שהאיברים מטיפוס רשימה יתווספו ל head אז נשלח לפונקציה build_list את כתובתו של head (כתובתו של ראש הרשימה). בתוך head מצויה הכתובת של האיבר הראשון ברשימה (נניח בכתובת 107a) ובכתובת זו יש ערכים - שם ,שם משפחה , משכורת וכתובת של האיבר הבא. הפרמטר של הפונקציה ()build_list הוא מצביע למצביע כך שכעת ערכו של head בפונקציה ()build_list ישב בכתובת חדשה - נניח fff0 (כתובת זה תמחק כאשר נצא מהפונקציה כי לא הקצנו אותה באופן דינאמי) והערך היושב בכתובת זו יהיה הכתובת של ה-head המקורי, כלומר fff4 (מסומן על ידי *head של הפונקציה ()build_list) וערכה של כתובת זו (כלומר **head של הפונקציה ()build_list) הוא האיבר הראשון של הרשימה המקורית.
כאשר אנו מוסיפים איברים אנו שולחים את הכתובת של head המקורי לפונקציה append. אנו מצהירים על שתי משתנים - last ו- n_nast כאשר last הוא משתנה סטאטי כלומר ערכו מאותחל בפעם הראשונה שנכנסים לפונקציה ולאחר מכן ערכו נשמר (בניגוד למשתנה רגיל המאותחל כל פעם שנכנסים לפונקציה וערכו מהכניסה הקודמת לפונקציה לא נשמר). תפקידו של משתנה זה לשמור על האיבר האחרון של הרשימה (מכיוון שכל פעם אנו מצרפים איבר לסוף אז משתנה זה מעודכן כל כניסה לפונקציה append). המשתנה n_last הוא מטיפוס רשימה ולכן שדהו הראשון הוא employee ואנו מזינים את השדה הזה ב emp שנשלח מהפונקציה ()read_data. שדהו השני הוא מצביע לאיבר מטיפוס רשימה אך מכיוון שאנו מעוניינים ש n_last יהיה כל פעם האיבר האחרון החדש (new last) אז רושמים כי שדהו השני יהיהNULL (כלומר סוף הרשימה). בודקים אם *head (שהוא הכתובת של ה head המקורי של פונקצית main) מכיל את הערך NULL אז זה סימן שהרשימה ריקה ולכן סוף הרשימה שווה לראש הרשימה. אחרת (כלומר הרשימה לא ריקה) המשתנה last יכיל את n_last והשורה לאחריו תמיד תתבצע (בין אם הרשימה ריקה או לא) - המשתנה last מקבל את כתובתו של n_last (כלומר סוף הרשימה מתעדכנת).
הפונקציה ()read_2_list מקבלת (כמו הפונקציה ()append ) את כתובתו של ראש הרשימה (המאוחסן ב *head של הפונקציה), מאחסנת ערך זה במשתנה temp ומדפיסה את ערכו של המשתנה temp לקובץ "employee.txt" . חשוב להשתמש במשתנה זמני (temp) מכיוון שאם לא הינו עושים זאת הינו מקדמים את *head ואז הינו מאבדים את האפשרות לגשת לכתובות הקודמות ולבדוק את ערכן. כשמקדמים את temp אין זה משפיע על המצביע של ראש הרשימה.
הפרמטר של הפונקציה ()Del_list הוא מצביע למצביע - אזי כמו שהסברנו קודם ערכו של *head יהיה הכתובת של ראש הרשימה המקורי, ולכן אנו שומרים כתובת זו במשתנה זמני (temp), מקדמים את ראש הרשימה *head = *head->next ומשחררים את הכתובת של ראש הרשימה הקודם על ידי פקודת free.
בפונקציה ()display אין צורך לשלוח את כתובתו של ראש הרשימה (כי לא מצרפים או מוחקים איברים - בסך הכל רוצים להציג את הערכים של הרשימה) ולכן הפרמטר של הפונקציה ()display הוא מצביע המכיל את התוכן של ראש הרשימה (ואילו תוכנו של ראש הרשימה הוא הכתובת של האיבר הראשון ברשימה) וכך שומרים את הכתובת של האיבר הראשון ברשימה מדפיסים את ערכיו ומתקדמים לאיבר הבא.
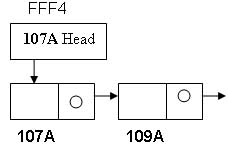 כאשר אנו שולחים את כתובתו של head (&head) לפונקציה שהפרמטר שלה הוא מצביע למצביע התמונה נראית כך:
כאשר אנו שולחים את כתובתו של head (&head) לפונקציה שהפרמטר שלה הוא מצביע למצביע התמונה נראית כך:
בניית רשימה על ידי רקורסיה
| |
void rec_append (struct node** head, int i)
{
if(*head)
rec_append (&(*head)->next,i);
else
{
*head = (struct node*)malloc(sizeof(struct node));
(*head)->num = i;
(*head)->next = NULL;
}
}
|
head מכיל את הכתובת של ראש הרשימה, *head את הכתובת של האיבר הראשון ברשימה. מכיוון שבתחילה הרשימה ריקה אז *head שווה ל-null ולכן מקצים באופן דינאמי מקום בזיכרון ל*head (האיבר הראשון ברשימה) וקובעים את שדותיו (כאשר השדה השני הוא null).
בפעם הבאה שנכנס לפונקציה *head יהיה שונה מ- null ולכן נקרא לפונקציה כאשר (*head)->next הוא האיבר השני ברשימה. מכיוון שזו הפעם השנייה שאנו נכנסים לרשימה - עוד אין איבר שני, הערך יהיה null, אז אנו נשלח את כתובתה לקריאה הבאה לפונקציה. כעת בכניסה הזו *headשווה ל-null ולכן מקצים ל"ראש הרשימה החדש" (שהוא האיבר השני) מקום בזיכרון ומאתחלים את שדותיו (מכיוון שהוא יהיה האיבר האחרון אז שדה השני יהיה null). כעת יוצאים מהעותק השני של הפונקציה לעותק הראשון וניתן לראות כי נוסף לנו האיבר שיצרנו לרשימה וכך הלאה - כלומר בונים את האיבר השלישי על ידי כניסה 3 פעמים לפונקציה, קובעים ערכים לאיבר יוצאים מהעותקים עד לעותק הראשון וכך הלאה.
מחיקת איברים על ידי רקורסיה
| |
void del_list (struct node** head)
{
if(*head)
{
printf("%p ",(*head)->next);
del_list (&(*head)->next);
free(*head);
}
else
{
gotoxy (1, wherey()-1);
printf ("Destruct list by deleting adresses: \n\n");
}
}
|
head מכיל את הכתובת של ראש הרשימה, *head את הכתובת של האיבר הראשון. בכניסה הראשונה *head שונה מ-null וערך ה-y הוא לדוגמא 15 . אזי מדפיסים את השני ברשימה ((*head)->next) וקוראים לפונקציה עם הכתובת של האיבר השני ברשימה. בכניסה הזו לפונקציה *head הוא האיבר השני ברשימה וכך הלא עד שנכנסים לקריאה האחרונה (האיבר האחרון). במקרה זה *head שווה ל-null, נכנסים ל- else מדפיסים את המשפט ויוצאים מהעותק האחרון. כזכור בעותק הלפני אחרון נכנסנו לגוף של פקודת ה- if (ולכן לא נדפיס את המשפט שוב).
*head הוא האיבר האחרון - אנו חוזרים לשורה שלאחר הקריאה לפונקציה ולכן נותר רק לבצע שחרור של האיבר האחרון ולחזור לקריאה הקודמת בה משוחרר האיבר לפני אחרון וכך הלאה עד לאיבר הראשון.
כעת נאחד את הפונקציות שהראנו לתוכנית אחת:
בניית צמתים על ידי רקורסיה, מחיקת צמתים על ידי רקורסיה.
דוגמא 4:
|
#include <stdio.h>
#include <conio.h>
const int MAX = 5;
struct node
{
int num;
struct node *next;
};
void rec_append (struct node** head, int i)
{
if(*head)
rec_append (&(*head)->next,i);
else
{
*head = (struct node*)malloc(sizeof(struct node));
(*head)->num = i;
(*head)->next = NULL;
}
}
void bulid_list (struct node** head)
{
int i;
for(i = 0; i < MAX; i++)
rec_append (head, i+1);
}
void display_list (struct node* head)
{
printf ("\n %s");
printf ("\nThe members of the list are: \n\n");
while (head != NULL)
{
printf (" %d ", head->num);
printf (" %p \n", head->next);
head = head->next;
}
}
void del_list (struct node** head)
{
if(*head)
{
printf("%p ",(*head)->next);
del_list (&(*head)->next);
free(*head);
}
else
{
gotoxy (1, wherey()-1);
printf ("Destruct list by deleting adresses: \n\n");
}
}
void delete_list (struct node** head)
{
printf("\n\nDeleting the list");
while (*head)
del_list (head);
}
void main()
{
struct node* head = NULL;
bulid_list (&head);
display_list (head);
del_list (&head);
}
|
רשימות עם יותר ממצביע אחד
ציינו שרשימה היא מבנה נתונים שבחלקו האחד כולל נתונים ובחלקו האחר מכיל מצביע לאיבר הבא ברשימה. חלק זה יכול לכלול מספר מצביעים לדוגמא: מצביע לאיבר הקודם ומצביע לאיבר הבא או מצביעים לשני איברים עוקבים (עץ בינארי) או מצביעים לשדות שונים.
יצירת רשימה עם שני מצביעים:
| |
void create_list (struct student** head)
{
struct student* b_last; //b_last = before last
struct student* last;
int i;
leng = MAX/2 + random(MAX/2);
printf ("\n\nInput %d random id numbers: \n");
b_last = *head;
for (i = 0; i < leng; i++)
{
last = (struct student*)malloc(sizeof(struct student));
last->id = random(1000)+6000;
last->grade = random(51)+50;
last->next_id = NULL;
last->next_grade = NULL;
b_last->next_id = last;
b_last->next_grade = last;
b_last = last;
}
}
|
מצהירים על שתי משתנים - b_last, last המייצגים את האיבר הלפני אחרון והאחרון שברשימה. האיבר הלפני אחרון (b_last) מכיל את הכתובת של האיבר הראשון של הרשימה, כעת נראה איך בונים את הרשימה על ידי שימוש בלולאה:
אנו מקצים מקום לאיבר חדש שהוא יהיה האיבר האחרון ברשימה (last), מאתחלים את שדותיו המספריים, ואת שדותיו הכתובתיים ל- null (כי אנו מעוניינים ש-last יהיה האיבר האחרון(. לאחר מכן גורמים ל b_last להצביע על last שהוא כזכור האיבר הראשון של הרשימה (מצרפים את אברי הרשימה החדשים לסוף הרשימה) ולבסוף b_last מכיל את last ושוב באיטרציה הבאה מקצים מקום לlast וגורמים ל- b_last להצביע על last וכך הלאה עד ש i=leng .
יש לשים לב כי הכתובות של המצביע ל- grade והמצביע ל-id הן אותן כתובות.
כעת נציג את התוכנית הבונה רשימה עם שני מצביעים וכן ממיינת את הרשימה לפי השדה id.
דוגמא 5:
|
#include <stdio.h>
#include <conio.h>
#include <stdlib.h>
#define MAX 7
int leng;
struct student
{
long id;
int grade;
struct student* next_id;
struct student* next_grade;
};
void create_list (struct student** head)
{
struct student* b_last;
struct student* last;
int i;
leng = MAX/2 + random(MAX/2);
printf ("\n\nInput %d random id numbers: \n");
b_last = *head; //b_last = before last
for (i = 0; i < leng; i++)
{
last = (struct student*)malloc(sizeof(struct student));
last->id = random(1000)+6000;
last->grade = random(51)+50;
last->next_id = NULL;
last->next_grade = NULL;
b_last->next_id = last;
b_last->next_grade = last;
b_last = last;
}
}
void write_list (struct student* head)
{
struct student* temp_id = head->next_id;
struct student* temp_grade = head->next_grade;
printf ("\nLIst by id numbers: \n");
while(temp_id)
{
printf ("\nId: %ld\t%p", temp_id->id, temp_id->next_id);
temp_id = temp_id->next_id;
}
printf ("\nLIst by grades: \n");
while(temp_grade)
{
printf ("\nGrade: %d\t%p", temp_grade->grade, temp_grade->next_grade);
temp_grade = temp_grade->next_grade;
}
}
struct student* place (struct student* head, int indx)
{
struct student* temp = head;
int i;
for (i = 0; i < indx; i++)
temp = temp->next_id;
return temp;
}
int place_id (struct student* head, int x)
{
int i;
struct student* temp;
temp = head;
for (i = 0; i < x; i++)
temp = temp->next_id;
return temp->id;
}
int bin_search (struct student* head, int leng, long x)
{
int first = 1;
int last = leng;
int mid = (first+last)/2;
while (first < last)
{
if (x < place_id (head, mid))
last = mid;
else
first = mid+1;
mid = (first+last)/2;
}
if (x == place_id (head, mid))
return mid;
else
return first;
}
void insert (struct student* head, int leng, long x)
{
struct student* temp;
struct student* temp1;
int new_indx;
new_indx = bin_search (head, leng, x);
if (new_indx == leng) return;
temp = place (head, new_indx); //new position in the list
temp1 = place (head, leng); //points to the last
place (head, leng-1)->next_id = temp1->next_id;
place (head, new_indx-1)->next_id = temp1;
temp1->next_id = temp;
}
void binary_sort (struct student** head)
{
struct student* temp;
int i;
printf ("\n\nThe list after sorting by id numbers:\n\n");
temp = *head;
for (i = 0; i <= leng; i++)
{
temp = place (*head, i);
insert (*head, i, temp->id);
}
}
void del_member (struct student** head)
{
struct student *temp = *head;
*head = (*head)->next_id;
printf ("%p\t", temp);
free(temp);
}
void del_list (struct student** head)
{
printf("\n\nDeleting the list\n");
while (*head)
del_member (head);
}
void main()
{
int leng;
struct student* head;
randomize();
head = (struct student*)malloc(sizeof(struct student));
head->id = 0;
head->grade = 0;
create_list (&head);
write_list (head);
binary_sort(&head);
write_list (head);
del_list (&head);
}
|
רשימה של פרטי סטודנט הכוללים ת.ז וציון, מצביע לציון ומצביע לת.ז. (למעשה אלו מצביעים לטיפוס 'סטודנט').
מיון הרשימה על פי ת.ז. - המיון שהוצג הוא מיון בינארי (למעוניין לקרוא על מיונים ימצא זאת בספרות על מבנה נתונים כפי שהזכרנו, לא נפרט את אופיו של המיון).
כדי לבצע מיון אנו יוצרים ראש דמה והמיון מתבצע ממנו והלאה (הנתונים בו לא רלוונטיים) - משתמשים בו כדי לא לאבד כתובות ברשימה לכן במחיקת הכתובות נוספו 2 כתובות, אחת מהן היא בעבור ראש הדמה והשנייה בעבור המצביע לראש הדמה.
מכיוון שהמצביע לת.ז ולציון בעלי אותה כתובת יש למחוק פעם אחת כל כתובת (כלומר למחוק מצביע לציון או מצביע לת.ז).
בהצגת הרשימה הודפסו הנתונים (ת.ז או ציון) בטור אחד ובשני השדה השני של הרשימה כלומר הכתובת של האיבר הבא.
|
|
 |
| © איתן 2003. כל הזכויות שמורות למערכת המידע איתן. |
|





 מבחן
מבחן

